-
BackpropagationAI\ML\DL/Deep learning theory 2023. 5. 7. 19:38반응형
Backpropagation
심층 신경망에서는
1. 특정 파라미터(weight/bias) 에 대한 Loss function의 편미분 값인 그래디언트를 구하고,
2. SGD (Stochastic gradient descent) 등의 Optimizer 로 최적의 파라미터를 업데이트한다.1번에서 신경망의 깊은 곳에 있는 weight 에 대한 편미분을 구하기 위해서는 Chain rule 을 활용해야 하는데,
Chain rule은 미분을 뒤로 전달하면서 곱하는 거니까 이 방법을 Backpropagation이라고 한다.
다음과 같은 신경망에서 Backpropagation을 통해 행렬로 표현된 weight 에 대해 loss function 을 미분해보자.
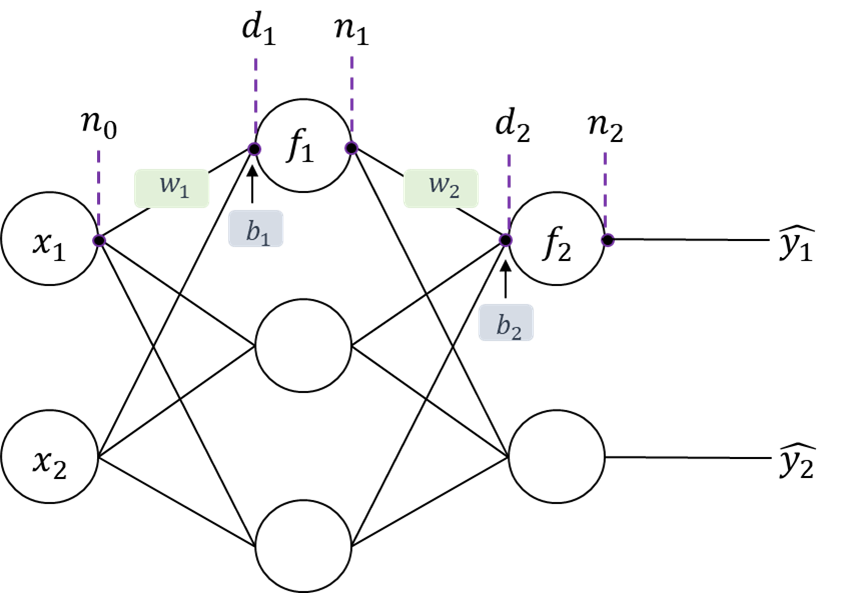
그림의 각 노드에 대해 다음과 같이 식을 쓸 수 있다.
$$\begin{align} & \textbf{d}_{1}=\textbf{n}_{0}\textbf{W}_{1}+\textbf{b}_{1}\\&\textbf{n}_{1}=\textbf{f}_{1}(\textbf{d}_{1})\\&\textbf{d}_{2}=\textbf{n}_{1}\textbf{W}_{2}+\textbf{b}_{2}\\&\textbf{n}_{2}=\textbf{f}_{2}(\textbf{d}_{2})\ \end{align}$$
Loss function은 $L=(\hat{y_{1}}-y_{1})^{2}+(\hat{y_{2}}-y_{2})^{2}$ 이다.
$\textbf{n}_{2}=[\begin{matrix}
\hat{y_{1}} & \hat{y_{2}} \\
\end{matrix}]$$$\begin {align*} L &=(\hat{y_{1}}-y_{1})^{2}+(\hat{y_{2}}-y_{2})^{2} \\&=(\textbf{n}_{2}-\textbf{y})(\textbf{n}_{2}-\textbf{y})^{T} \\ &= (\left [ \begin{matrix} \hat{y_{1}} & \hat{y_{2}} \\ \end{matrix} \right ]-\left [ \begin{matrix} y_{1} & y_{2} \\ \end{matrix} \right ])(\left [ \begin{matrix} \hat{y_{1}} \\ \hat{y_{2}} \end{matrix} \right ]-\left [ \begin{matrix} y_{1} \\ y_{2} \end{matrix} \right ]) \\&=\left [ \begin{matrix} \hat{y_{1}}-y_{1} & \hat{y_{2}}-y_{2} \\ \end{matrix} \right ]\left [ \begin{matrix} \hat{y_{1}}-y_{1} \\ \hat{y_{2}}-y_{2} \end{matrix} \right ] \\&= (\hat{y_{1}}-y_{1})^{2}+(\hat{y_{2}}-y_{2})^{2} \end{align*} $$
즉, Loss function 을 $L=(\textbf{n}_{2}-\textbf{y})(\textbf{n}_{2}-\textbf{y})^{T}$ 와 같이 벡터로 나타내었다.
$L$ 을 행렬 $W$ 로 미분하기 위해 $W$ 를 벡터화 할 것이다.
$$\mathbf{w_{1}}=\textrm{vec}(\mathbf{W_{1}})$$
$$\mathbf{w_{2}}=\textrm{vec}(\mathbf{W_{2}})$$
$L$ 이라는 벡터함수를 $\mathbf{w}$ 이라는 벡터로 편미분하려면 chain rule 을 사용할 수 있다.
(참고하기 https://deep-learning-basics.tistory.com/1 5번)
다변수 함수의 미분
1. 편도함수 일변수 함수 $f: ℝ \rightarrow ℝ$ 의 도함수 $f' (x) $ 은 다음과 같이 정의한다. $ f' (x)= \displaystyle \lim_{h \to 0}\frac{f(x+h)-f(x)}{h} $ 일변수 함수 $f $ 의 도함수 $f' $ 은 점 $x$에서 '$x$ 가 변할
deep-learning-basics.tistory.com
$$\frac{\partial L}{\partial \mathbf{w^{T}_{2}}}=\frac{\partial \textbf{d}_{2}}{\partial \mathbf{w^{T}_{2}}}\frac{\partial \textbf{n}_{2}}{\partial \mathbf{d^{T}_{2}}}\frac{\partial L}{\partial \mathbf{n^{T}_{2}}} \tag{1}$$
$$(\textbf{w}_{2}\to\textbf{d}_{2}\to \textbf{n}_{2}\to\textbf{L})$$
$$\frac{\partial L}{\partial \mathbf{w^{T}_{1}}}=\frac{\partial \textbf{d}_{1}}{\partial \mathbf{w^{T}_{1}}}\frac{\partial \textbf{n}_{1}}{\partial \mathbf{d^{T}_{1}}}\frac{\partial \mathbf{d_{2}}}{\partial \mathbf{n^{T}_{1}}}\frac{\partial \textbf{n}_{2}}{\partial \mathbf{d^{T}_{2}}}\frac{\partial L}{\partial \mathbf{n^{T}_{2}}} \tag{2}$$
$$(\textbf{w}_{1}\to\textbf{d}_{1}\to \textbf{n}_{1}\to \textbf{d}_{2}\to \textbf{n}_{2}\to L)$$
앞에서 뒤쪽으로 미분하고 곱하여 편미분을 구했다.
식 (1) 부터 미분값을 구해보자.
$$\begin{align} & \frac{\partial \textbf{d}_{2}}{\partial \textbf{w}^{T}_{2}}=\textbf{n}_{1}^{T}\otimes\textbf{I} \\& \frac{\partial \textbf{n}_{2}}{\partial \textbf{d}^{T}_{2}}=\textrm{diag}(\textbf{f}_{2}^{'}(\textbf{d}_{2})) \end{align}$$
식 (2) 를 계산하면 다음과 같다.
$$\begin{align} & \frac{\partial \textbf{d}_{1}}{\partial \mathbf{w^{T}_{1}}}=\textbf{n}_{0}^{T}\otimes\textbf{I} \\& \frac{\partial \textbf{n}_{2}}{\partial \mathbf{d^{T}_{2}}}=\textrm{diag}(\textbf{f}_{1}^{'}(\textbf{d}_{1})) \\& \frac{\partial \mathbf{d_{2}}}{\partial \mathbf{n^{T}_{1}}}=\textbf{W}_{2} \\& \frac{\partial \textbf{n}_{2}}{\partial \textbf{d}^{T}_{2}}=\textrm{diag}(\textbf{f}_{2}^{'}(\textbf{d}_{2})) \\& \frac{\partial L}{\partial \mathbf{n^{T}_{2}}}=2(\textbf{n}^{T}_{2}-\textbf{y}) \end{align}$$'AI\ML\DL > Deep learning theory' 카테고리의 다른 글
이진분류에서 Maximum Likelihood Estimation (MLE) (2) 2023.05.10 Logistic Regression (0) 2023.05.08 Momentum, RMSProp Optimizer (1) 2023.05.06 Stochastic Gradient Descent (3) 2023.05.06